AWS S3 Storage Pricing: Costs, Tiers, and Tradeoffs
If you are trying to estimate AWS S3 storage pricing, the hard part is not the headline price per GB. It is everything around it: storage class choice, request fees, retrieval charges, transfer costs, minimum storage duration, metadata overhead, replication, and the operational tradeoffs that show up later in the bill.
For AI engineers, ML teams, and developer-first startups, this matters more than most storage guides admit. Datasets, model checkpoints, embeddings, logs, renders, and artifacts grow fast. A cheap-looking storage tier can become expensive when paired with frequent GETs, inter-region traffic, or archive restores. And when you run GPU workloads, storage design directly affects experiment speed and infrastructure cost.
This guide breaks down AWS S3 cost per GB and per TB, explains storage class pricing and API fees, and shows where S3-compatible storage can be a better fit, especially when you want simpler pricing and tighter integration with GPU workflows.
"Amazon Simple Storage Service (S3) is designed to provide 99.999999999% (11 nines) data durability." - AWS Documentation
"By 2025, global data creation, capture, and storage is projected to reach 175 zettabytes, with cloud storage accounting for 80% of all data storage." - WorldMetrics
What AWS S3 pricing actually includes
Most articles reduce S3 pricing to a storage table. That is incomplete. In practice, AWS S3 object storage pricing is made of several separate meters:
storage used, by class
PUT, GET, LIST, COPY, POST, and lifecycle requests
retrieval fees for colder classes
transfer out to the internet
inter-region transfer
monitoring and analytics features
replication
encryption-related KMS costs
special products like S3 Tables, S3 Vectors, S3 Express One Zone, and S3 Files
For most teams, the main bill comes from five categories:
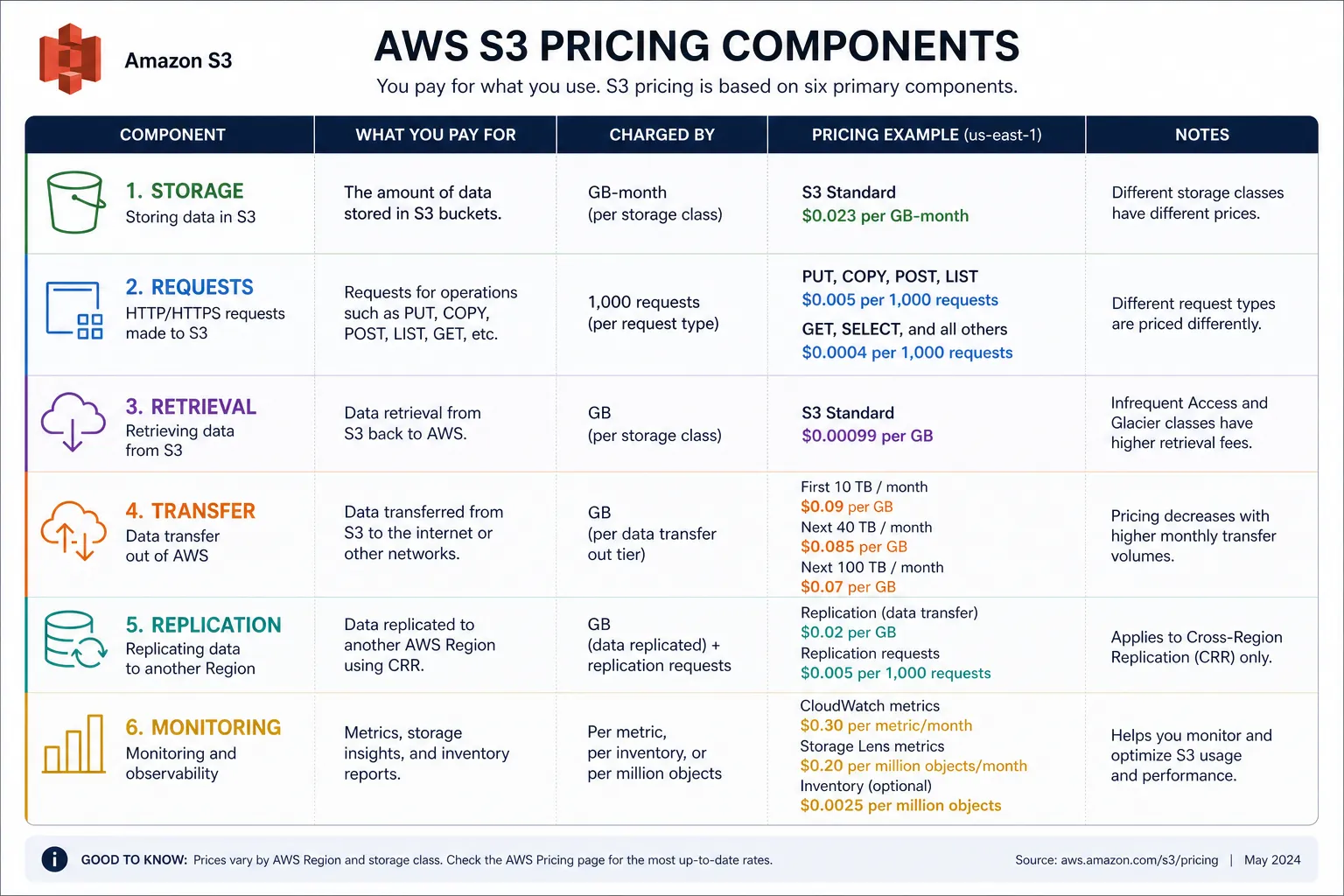
Cost component | What it means | Why it matters |
|---|---|---|
Storage | GB stored per month in a specific class | Your base recurring cost |
Requests | API calls like PUT, GET, LIST | Small files and frequent reads add up |
Retrieval | Fees to read from IA and Glacier tiers | Cheap storage can become costly to access |
Data transfer | Outbound internet or cross-region movement | A major hidden cost in production |
Replication and management | CRR, inventory, analytics, monitoring | Often ignored during architecture planning |
Why S3 pricing feels more complex than it should
Competitor guides usually cover the big storage classes, but they often gloss over the things that actually surprise engineers in production:
Request-heavy workloads distort the bill
A pipeline with millions of small objects can spend disproportionately on API calls. This is common in:
image preprocessing datasets
chunked training corpora
document pipelines
inference caches
rendering outputs
logs and telemetry archives
Cold storage has access penalties
S3 Standard-IA and Glacier classes look cheap on paper, but retrieval and minimum retention rules can erase the savings if your access pattern is wrong.
Data transfer is architecture-dependent
Moving data between regions, or pulling it to the public internet, can cost more than the storage itself. For ML systems, repeatedly pulling artifacts into compute can become wasteful fast.
S3 pricing is optimized for AWS-native architectures
If your compute, networking, and storage all live inside AWS, S3 works well. If your team wants a leaner GPU cloud plus S3-compatible storage, the economics can shift.
That is where BHK Cloud becomes interesting: simpler S3-compatible storage, zero egress fees between GPU and storage, fast deployment, and no hyperscaler-style complexity when you are just trying to train, fine-tune, render, or ship.
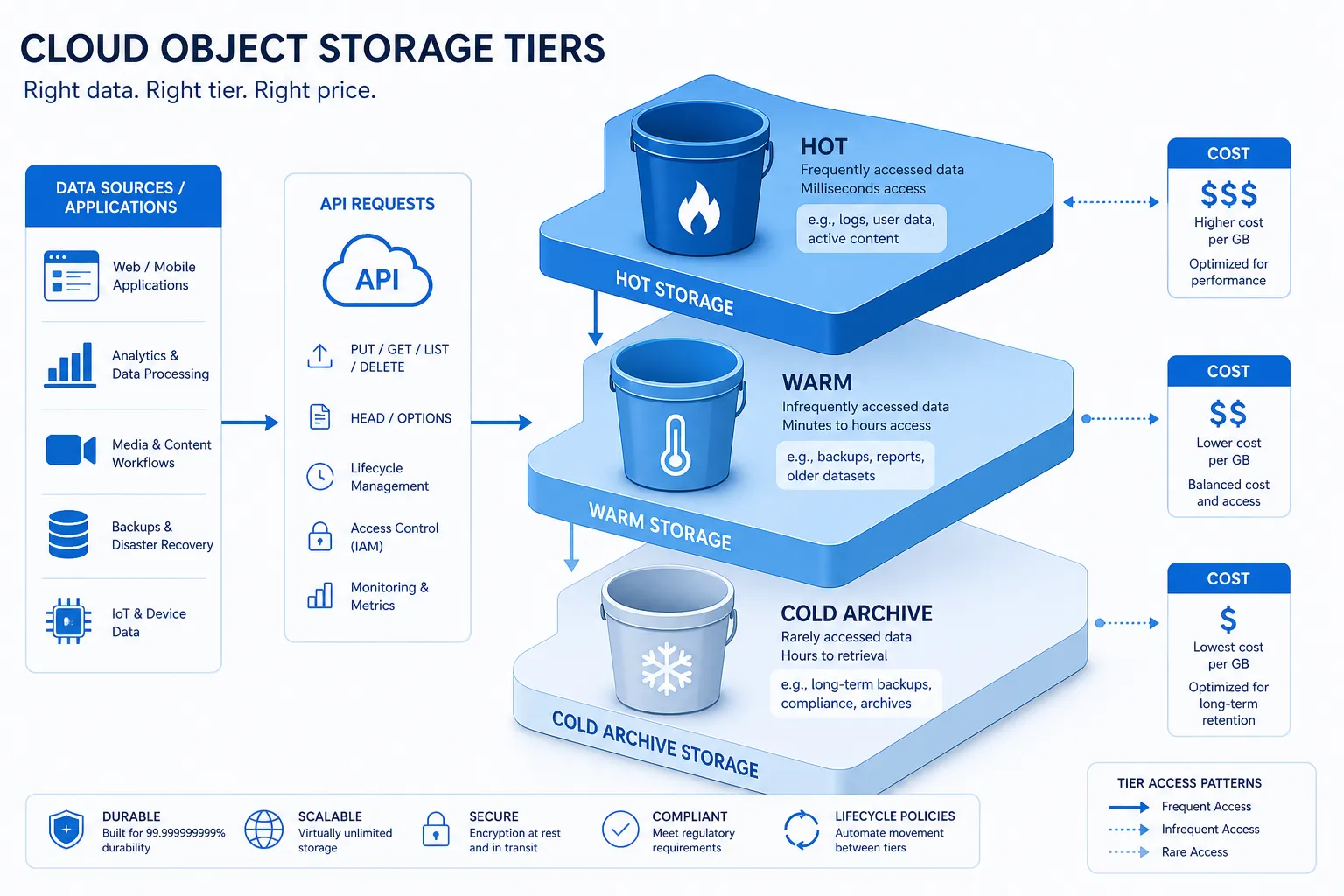
AWS S3 storage pricing by storage class
Below is the practical view of AWS S3 storage class pricing based on the common US East baseline shown in AWS pricing material. Exact rates vary by region, but these are the numbers most teams use for rough planning.
Core S3 storage classes and baseline rates
Storage class | Typical use case | Approx. storage price |
|---|---|---|
S3 Standard | Frequently accessed data | $0.023 per GB/month for first 50 TB |
S3 Intelligent-Tiering Frequent Access | Unknown/changing access patterns | $0.023 per GB/month |
S3 Standard-IA | Infrequent but fast access needed | $0.0125 per GB/month |
S3 One Zone-IA | Re-creatable data, single AZ | $0.01 per GB/month |
S3 Glacier Instant Retrieval | Archive with millisecond access | $0.004 per GB/month |
S3 Glacier Flexible Retrieval | Cold archive, minutes to hours restore | $0.0036 per GB/month |
S3 Glacier Deep Archive | Long-term archive | $0.00099 per GB/month |
S3 Express One Zone | High-performance single AZ storage | $0.11 per GB/month |
What 1 TB roughly costs in each class
Assuming 1 TB = 1,024 GB and ignoring request, retrieval, and transfer charges:
Storage class | Approx. monthly cost for 1 TB |
|---|---|
S3 Standard | $23.55 |
S3 Intelligent-Tiering FA | $23.55 plus monitoring fee |
S3 Standard-IA | $12.80 |
S3 One Zone-IA | $10.24 |
Glacier Instant Retrieval | $4.10 |
Glacier Flexible Retrieval | $3.69 |
Glacier Deep Archive | $1.01 |
S3 Express One Zone | $112.64 |
If you are searching for AWS S3 cost per TB, this is the cleanest starting point. But it is only the starting point.
AWS S3 storage cost per GB: what changes the real number
The advertised AWS S3 storage cost per GB is the raw capacity price. Your actual effective rate changes based on the following.
Minimum object size rules
Some tiers have minimum billable object sizes, especially IA and Glacier Instant Retrieval. If you store small objects, you may be billed as though they are larger than they really are.
Minimum storage duration
Standard-IA and One Zone-IA: 30 days
Glacier Instant Retrieval and Glacier Flexible Retrieval: 90 days
Glacier Deep Archive: 180 days
Delete or move objects too early, and AWS still charges the remaining minimum duration.
Metadata overhead in Glacier classes
Archived objects can carry additional metadata billing. This becomes noticeable at very high object counts.
Monitoring fees in Intelligent-Tiering
Intelligent-Tiering adds a per-object monitoring and automation fee. It is often worth it for unknown access patterns, but not always for massive numbers of tiny objects.
AWS S3 request pricing and API fees
S3 API pricing is the part many teams underestimate. Request-heavy designs can produce meaningful costs even when total storage is modest.
Common request prices
Approximate baseline in US East:
Request type | S3 Standard | Standard-IA / One Zone-IA | Glacier Instant Retrieval |
|---|---|---|---|
PUT, COPY, POST, LIST | $0.005 per 1,000 | $0.01 per 1,000 | $0.02 per 1,000 |
GET and other reads | $0.0004 per 1,000 | $0.001 per 1,000 | $0.01 per 1,000 |
What that means in practice
Example: 100 million GET requests in S3 Standard
100,000,000 / 1,000 = 100,000 units
100,000 × $0.0004 = $40
That is not terrible. But now combine it with:
millions of PUTs from preprocessing
LIST operations from indexers
lifecycle transitions
HEAD requests from applications
retrieval charges in colder tiers
The bill becomes less trivial.
Where this hits ML and app teams hardest
You will notice S3 GET pricing most when you have:
many small training shards
frequent metadata lookups
image generation pipelines reading reference assets
inference systems pulling model artifacts repeatedly
render workloads reading and writing many intermediate files
This is why storage architecture is part of compute optimization. Cheap GPU time can be wasted by noisy storage patterns, and cheap storage can be offset by API churn.
Data retrieval fees: the trap behind cheaper storage classes
Not all S3 reads are equal.
Storage classes with retrieval charges
S3 Standard: no retrieval charge
S3 Intelligent-Tiering: no retrieval charge for standard access tiers
Standard-IA: retrieval charge per GB
One Zone-IA: retrieval charge per GB
Glacier Instant Retrieval: retrieval charge per GB
Glacier Flexible Retrieval: restore request and retrieval pricing
Glacier Deep Archive: restore request and retrieval pricing
Practical tradeoff
If you have a 2 TB dataset that is read weekly, Standard-IA may look cheaper than Standard on storage alone. But if your team repeatedly scans or downloads that data, total cost may exceed Standard.
That is why the right question is not “what is the cheapest S3 tier?” It is “what is the cheapest tier for my access pattern?”
Data transfer pricing: the part that frustrates teams most
Transfer pricing is where hyperscaler complexity becomes operational pain.
Standard outbound transfer from S3 to internet
Typical public internet egress in US East begins around:
first 100 GB/month: free across AWS services
next usage tier: about $0.09 per GB
This can dwarf storage cost quickly.
Transfer between regions
Cross-region movement is billed. Replication also adds data transfer and destination storage costs.
Transfer to services in the same region
Some paths are free or discounted, but the exact behavior depends on service and architecture.
Why this matters for AI infrastructure
If your storage sits in one place and your GPU compute somewhere else, you can bleed money and time on data movement.
BHK Cloud solves a simpler, more modern version of this problem for AI teams:
RTX 3090 GPU deployment in under 60 seconds
S3-compatible storage for datasets, checkpoints, and outputs
zero egress fees between GPU and storage
API-first and CLI-friendly workflows
no lock-in or enterprise sales friction
For teams doing inference, fine-tuning, rendering, and iterative experiments, that can be a cleaner model than stitching together high-cost compute and separately metered storage on a hyperscaler.
S3 pricing examples you can use for planning
Example 1: 1 TB in S3 Standard with moderate app traffic
Assumptions:
1 TB stored
5 million GET requests
500,000 PUT/LIST requests
no significant transfer out
Estimated monthly cost:
storage: 1,024 × $0.023 = $23.55
GET: 5,000 × $0.0004 = $2.00
PUT/LIST: 500 × $0.005 = $2.50
Total: about $28.05/month
Example 2: 10 TB archive in Glacier Deep Archive
Assumptions:
10 TB stored
almost no retrieval
no heavy request activity
Estimated monthly cost:
10,240 GB × $0.00099 = $10.14/month
Extremely cheap, but only if your restore expectations are measured in hours and your retention fits the 180-day minimum.
Example 3: 5 TB inference artifact store with internet egress
Assumptions:
5 TB in Standard
low API usage
2 TB/month public egress
Estimated monthly cost:
storage: 5,120 × $0.023 = $117.76
data transfer out: 2,048 × $0.09 = $184.32
Total: about $302.08/month, with transfer now dominating storage.
This is the kind of example many competitor posts fail to emphasize.
AWS S3 pricing tradeoffs by workload type
For active application assets
Use S3 Standard when you need:
low latency
frequent reads
no restore delays
no retrieval fees
For unpredictable access patterns
Use Intelligent-Tiering when:
you do not know future access frequency
objects are not tiny in huge counts
you want automation over manual lifecycle rules
For backups and disaster recovery
Standard-IA or One Zone-IA can make sense when:
access is infrequent
restore speed still matters
the data is large enough to justify the tier
single-AZ durability is acceptable for One Zone-IA
For long-term archive
Use Glacier classes when:
retrieval is rare
latency can be minutes or hours
compliance retention matters
you understand the minimum retention rules
For ultra-high-performance niche use
S3 Express One Zone is for specialized high-performance scenarios, not generic cheap object storage.
AWS S3 vs S3-compatible storage: where the economics diverge
For many developers, S3 has become shorthand for object storage. But S3-compatible storage is not the same thing as AWS S3 pricing.
What S3-compatible storage means
It means the storage supports the S3 API model closely enough to work with common tools, SDKs, and client workflows.
That matters because it gives teams portability without forcing them into AWS’s full pricing model.
Where AWS still wins
AWS S3 remains strong when you want:
deep integration with AWS services
broad ecosystem maturity
global availability options
advanced features across many storage products
Where S3-compatible alternatives can win
They are attractive when you want:
clearer pricing
less billing fragmentation
lower transfer cost
easier compute-to-storage locality
fewer enterprise abstractions
simpler developer operations
Why BHK Cloud is a compelling alternative for AI and GPU-heavy teams
This article is about AWS S3 storage pricing, but for many readers the real question is not “how does S3 work?” It is “what should I use for modern AI infrastructure without hyperscaler bloat?”
BHK Cloud is built for that exact use case.
What stands out
Area | BHK Cloud advantage |
|---|---|
GPU compute | Much lower GPU pricing than major hyperscalers |
Billing | Transparent hourly usage, no lock-in |
Deployment | Fast provisioning, typically under 60 seconds |
Developer workflow | API-first, CLI-friendly experience |
GPU hardware | RTX 3090 with 24 GB VRAM, well suited for inference, fine-tuning, rendering, and experimentation |
Storage | S3-compatible object storage with existing SDK/tool compatibility |
Network economics | Zero egress fees between GPU and storage |
Data controls | Persistent volumes, snapshots, versioning, lifecycle rules |
Platform design | Clean infrastructure without unnecessary enterprise complexity |
Why this matters operationally
If your team is iterating on models, pipelines, or image generation systems, infrastructure speed is not just about benchmark numbers. It is about how quickly you can:
spin up compute
pull model assets
write checkpoints
persist outputs
share artifacts
tear down resources
control spend without long procurement loops
A storage platform that behaves like S3, but is packaged around AI workflows instead of general-purpose hyperscaler complexity, can be the better engineering choice.
Cost comparison mindset: what to compare beyond price per GB
When evaluating AWS S3 cloud storage against an S3-compatible option, compare these factors, not just the raw storage rate.
Dimension | Questions to ask |
|---|---|
Storage cost | What is the true per-GB and per-TB rate? |
Request cost | Are GET, PUT, LIST, and lifecycle operations separately billed? |
Retrieval cost | Are colder tiers penalized? |
Data transfer | Is there egress to internet, inter-region, or compute? |
Compute locality | Is storage near my GPU jobs? |
Operational simplicity | Do I need multiple AWS services to achieve a basic workflow? |
API compatibility | Will my existing tools work without changes? |
Team velocity | Can developers self-serve quickly? |
This is where BHK Cloud’s position is unusually practical. It is not trying to be every cloud service. It is trying to be the infrastructure AI teams actually need.
Common mistakes teams make with S3 storage pricing
Choosing the cheapest storage tier by default
Archive economics only work when access is truly rare.
Ignoring request volume
Object count and access frequency matter almost as much as total bytes.
Underestimating transfer out
Public egress can dominate your bill.
Using tiny objects in the wrong class
Minimum billable size and monitoring fees can destroy efficiency.
Designing storage separately from compute
For ML and rendering, storage and compute are one system.
A practical decision framework
Choose AWS S3 if:
you are deeply invested in AWS-native services
you want mature, broad ecosystem support
your team accepts granular billing complexity
you need specific AWS integrations
Choose an S3-compatible platform like BHK Cloud if:
you want predictable infrastructure for AI workloads
your team needs affordable GPUs and object storage together
you care about zero egress between compute and storage
you want faster provisioning and less platform overhead
you prefer transparent hourly billing and no lock-in
Final verdict
AWS S3 pricing is not bad. It is just layered. The advertised storage rate is only one part of the total cost. Real-world S3 pricing depends on storage class, object size, request mix, retrieval patterns, transfer behavior, replication, and how close storage is to your compute.
For conventional enterprise architectures, AWS S3 remains a strong default. But for AI engineers, ML practitioners, technical startups, and product teams running data-heavy GPU workflows, there is a growing gap between what hyperscalers offer and what developers actually need.
BHK Cloud fits that gap well: lower-cost RTX 3090 compute, S3-compatible storage, zero egress between GPU and storage, fast deployment, usage-based billing, and a clean API-first platform without enterprise bloat. If you are building inference systems, training pipelines, image generation stacks, or rendering workflows, that combination is often more useful than raw brand familiarity.
If you want object storage that works like S3 but feels built for modern AI infrastructure, BHK Cloud is worth trying.
What is the S3 pricing tier?
An S3 pricing tier refers to the storage class and its billing model, such as S3 Standard, Standard-IA, Intelligent-Tiering, or Glacier. Each tier changes your cost based on access frequency, retrieval speed, and durability model.
What are the tiers of S3 storage?
The main Amazon S3 tiers include S3 Standard, Intelligent-Tiering, Standard-IA, One Zone-IA, Glacier Instant Retrieval, Glacier Flexible Retrieval, Glacier Deep Archive, and S3 Express One Zone. They range from hot storage for active data to ultra-low-cost archival storage for rare access.
Which Amazon S3 storage class has the lowest cost?
S3 Glacier Deep Archive has the lowest raw storage cost, at roughly $0.00099 per GB per month in common US pricing examples. It is best for long-term archival because restores are slow and minimum retention rules apply.
What are the pricing options for Amazon S3?
Amazon S3 pricing includes storage charges, API request fees, retrieval fees, data transfer costs, replication costs, and optional management or analytics charges. Your final bill depends on both the storage class and how your application reads, writes, and moves data.
What are the different types of S3 tiers?
The different S3 tiers are generally grouped as frequent-access, infrequent-access, archival, and high-performance specialized storage. In practice, that means Standard for active use, IA for cooler data, Glacier for archives, and Express One Zone for performance-sensitive workloads.
How much does 1TB of storage cost in S3?
For S3 Standard, 1 TB is about $23.55 per month before requests, retrievals, and transfer fees. In colder classes like Glacier Deep Archive, 1 TB can drop to around $1.01 per month, but access becomes slower and less flexible.